Introduction
Orbit Determinator is a project that aims to provide satellite’s tracking information to various researchers, university students and space enthusiasts who plan to launch their satellites (mainly CubeSats) into space.
The central idea to accomplish this is the position of the satellite at different time instances and then perform filtering and preliminary orbit determination techniques to get keplerian elements of the orbit. A CSV file is taken as input which has values in the format: (time, x-coordinate, y-coordinate, z-coordinate). This input sample has lots of jitter to perturbation and has to be. This project was carried out with Alexandros Kazantzidis under the guidance of Andreas Hornig.

Before the coding period started, I had already tried some smoothing / filtering techniques like as convolution and exponential smoothing with varying parameters and had an idea how to go about making changes.
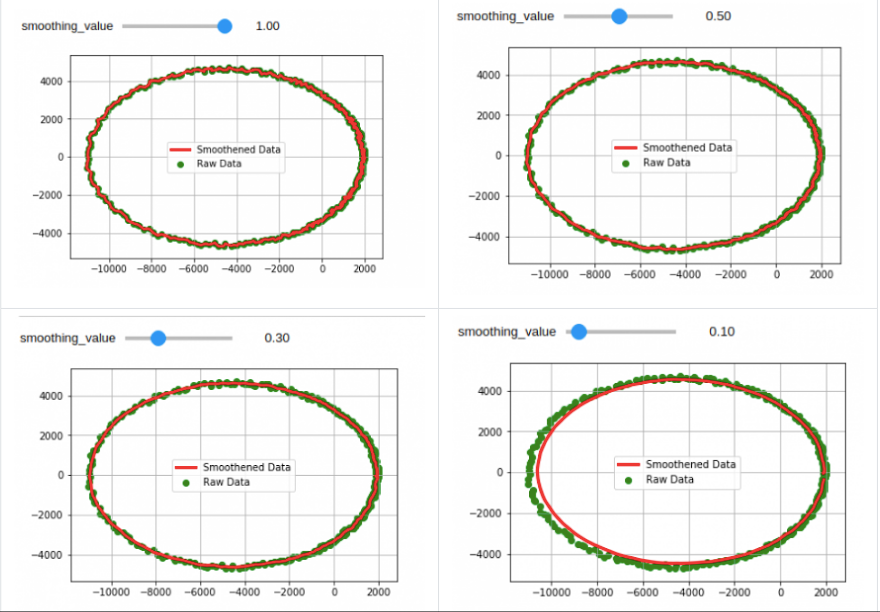
Project Setup and Filter Design
The project started with initializing repositories and required services such as TravisCI and Codacy on Github and writing API to parse input data. Next, I started trying different combinations of convolutional filters and dived into AutoRegressive Integrated Moving Average(ARIMA) models. Having read about filters in this category, I made some changes in conventional convolutional filters to come up with the triple moving average filter. This filter gave better results than any of the previous techniques. The filter’s parameters had to be tuned to give best results.
Setting Up Automated Documentation and Testing
Writing documentation separately in the scripts as comments and in the repository seemed to be a repetitive and laborious task. In consent with my teammate and my mentor, we decided to opt for automated documentation which would pull the comments in the form of doc-strings from the scripts itself and generate documentation. We decided to use Sphinx as the automated documentation tool. For the style of doc-strings, we used the Google Style. I configured this tool and hosted it on readthedocs. Having done this, I moved to testing and for testing, we used pytest as the tool for testing which was added to TravisCI configuration also. I wrote some tests for the scripts I created.
Interpolation as a method for Orbit Determination
While I was involved in the above-mentioned tasks, my project partner Alexandros had already implemented some conventional methods for orbit determination namely Lambert’s method and Gibbs method. Gibbs methods took too long to compute the results and we had just one method for orbit determination. Andreas had an idea that this could somehow also be done using interpolation. So basically, all that is needed to calculate orbit parameters is the „State vector“ which comprises of position vector and velocity vector of the satellite at a point. Since we had the position of the satellite at given intervals of time, state vector could be obtained if we could fit a curve passing through all these points. Many interpolation methods including linear interpolation, Newton’s Divided Difference interpolation, and Spline interpolation were on the list out of which Spline Interpolation seemed to be the best option(the other two had some drawbacks like Runge’s phenomenon when applied to the kind of data we had). Among splines, although quadratic splines could do the job(since we needed only twice derivable splines), the Cubic splines have an edge over quadratic splines, also the result was better in the latter case. So I implemented Cubic spline interpolation as the orbit determination method.
Server Deployment
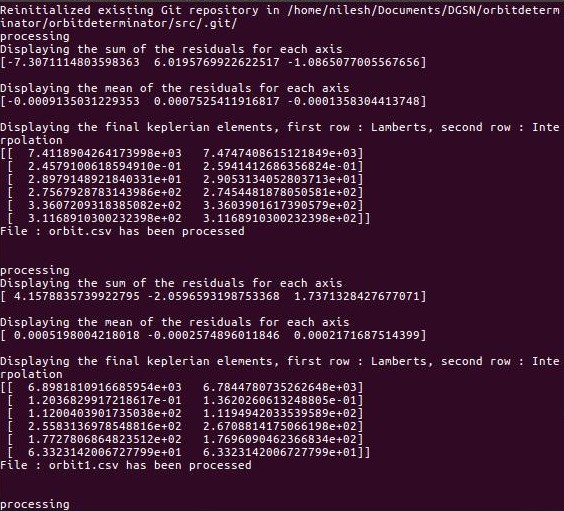
The need of this project is such that, when deployed on the server, it should be able to automatically read the new CSV file, process them and store the work products. To implement this efficiently, a technique was needed which could identify the new/unread/unprocessed files that came into the system. For doing that I went ahead with Git VCS which had inbuilt support for the same. I wrote a script which would initialize git in the directory where new files would be added. New files would be read, processed and staged(git add file1 file2 ...) and this would be run in an infinite loop. This ensures that the already processed files will not be read and processed repeatedly. Below is a sample of console output of this script.
Binding it all up
Having made all the core modules of the project, the next task was to pull it all together in one script. Doing this for a single file was already done by Alexandros, I had to make the server deployable version. 2 filters namely Savitzky-Golay and Triple Moving Average are being used in the current version. The parameters of these filters had to be tuned. The parameters of both these filters were varied and error was calculated on a large dataset. Since dataset was huge, and I had a system with limited resources, a parallelizable code had to be written which would utilize all the available processing power and fetch the results in reasonable time. Statistics indicated that in general, the results were best when the window size of Triple moving average is 3, polynomial used for Savitzky-Golay is 3, the window size of same had to be estimated depending upon the number of points in the input.
Future Plans
The idea until now has been implemented keeping in mind the most general and frequently occurring scenarios. Many other circumstances although rare, but theoretically still have chances to occur. A number of such cases have to be covered. Support for more number of work products can be added to make it easy and intuitive for the end user to analyze.
Useful links
- Source Code : The source code for this project can be viewed on Github .
- Documentation : The documentation contains all the information related to the modules along with 3 tutorials for the users. It is available on readthedocs .
- Commits: Visit here to have a look at the commits I made in this project.
- My Github’s profile : My work can be viewed here .