ESDC (Evolutionary System Design Converger) is a software suite designed for optimization of complex engineering systems. ESDC uses system modelling equations, a database containing data points of existing systems, system scaling equations as well as mission requirements to design systems that fulfill their design objectives in the most efficient and effective way.
GSoC 2019 Contribution
The heart of ESDC’s optimization process is a genetic algorithm. The algorithm takes an initial population of design points and navigates the design space using a series of operations that are inspired from natural selection, such as mutation of permitted design degrees of freedom and subsequent selection, . One optimization cycle produces a lot of data and need to be analyzed and examined in order to acquire insight about the optimal designs, the performance of the algorithm and the design space in general.
My contribution to the project is a flexible multi-dimensional visualization and animation system designed for exploration of the system’s evolution data. The system uses various visual aspects of the generated visualizations in order to encode more degrees-of-freedom that would normally be possible in a simple 2-d or 3-d plot, thus allowing the exploration of complex systems. The definition of the visualizations is achieved through a user-defined XML file, where a plethora of options for customizing the content, the features and the annotation of the visualizations is available. The visualization system also has the ability to animate the generated figures, thus visually recreating the progress of the optimization.
Although the planned key features have all been implemented,
there is always room for improvement and as the ESDC project is growing additional
needs will arise. Currently, the main future work identified is:
-) Improved integration with ESDC, specifically automatically
acquiring names and units of the system’s degrees-of-freedom which can be used
in all annotations.
-) Automatic generation of additional data from data to
understand reasoning behind the final design. For example, presenting the
relevant data, where designed subsystems rely on.
During the previous coding periods the key functionality
that was planned for this project was implemented. Thus, during the final
coding period there was time for improvements, development of one additional
feature whose inspiration came up during the previous period, refactoring and
organizing the file structure of the code as well as documenting the implemented
tool for feature users or developers.
First, the
following improvements were made:
-) The way
in which the minimum and maximum value of a continuous degree-of-freedom is
calculated was adjusted. Previously the minimum and maximum value was
calculated from the aggregate of the evolution data, which includes all lineages
and generations of the genetic optimization process. Now these values are
calculated specifically for each visualization scenario, only from the relevant
lineages and generations according to user defined options.
-) The part
of the code responsible for generating the animations was refactored and
extended to include the option to save the animations as compressed gif files.
The need for this arose after finding that the size of the gif files would
easily grow to tenths of megabytes even for the simple optimization scenarios
examined here.
Next, an
additional type of graphic, which allows for the visualization of useful
subsystems’ information on top of the existing 2d or 3d visuals was
implemented. This is a stacked bar graph spanning the y-axis on the 2d plots
and the z-axis on the 3d plots. The units of the stacked bar graphs are the
same as the units of the corresponding axis that it’s spanning. The height of
the individual bars of a stack are proportional to the values of the
corresponding degree-of-freedom of the respective subsystems that each bar is
representing.
Currently,
the stacked bar graphs are used to visualize the distribution of the electric
propulsion system’s total mass fraction into the corresponding subsystems.
Thus, the stacked bar graphs can be used to explore how the mass fraction of
each individual subsystem is changing as the genetic algorithms navigates
through different design points. To better understand this, let’s explore two
examples.
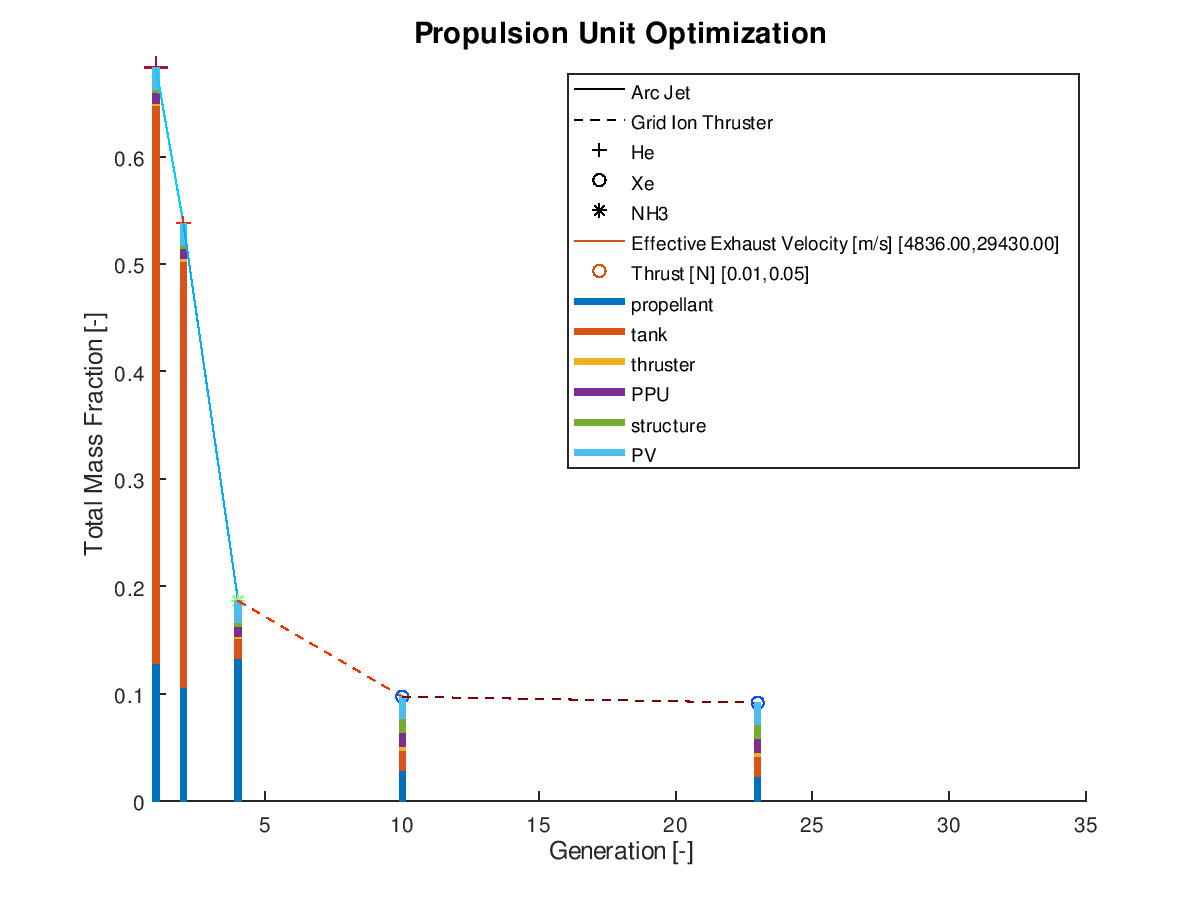
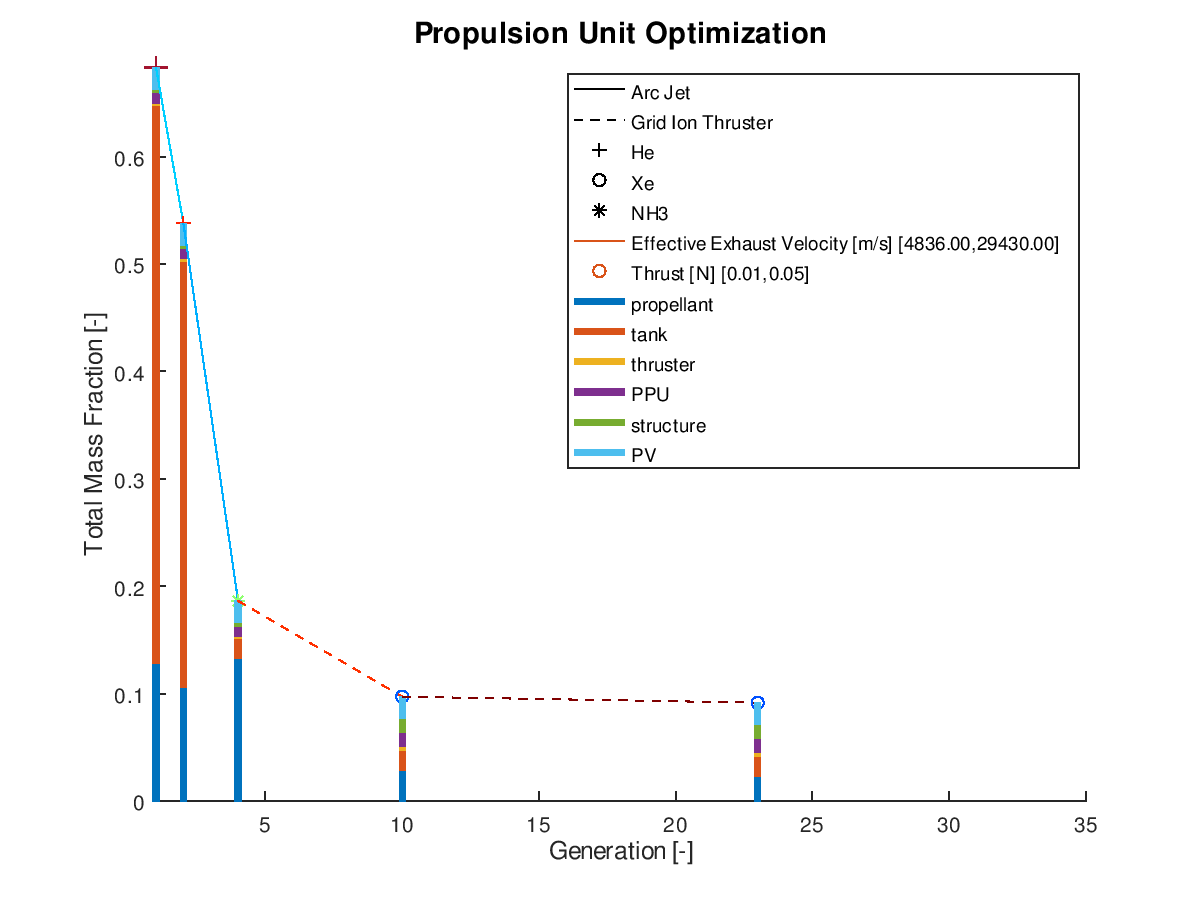
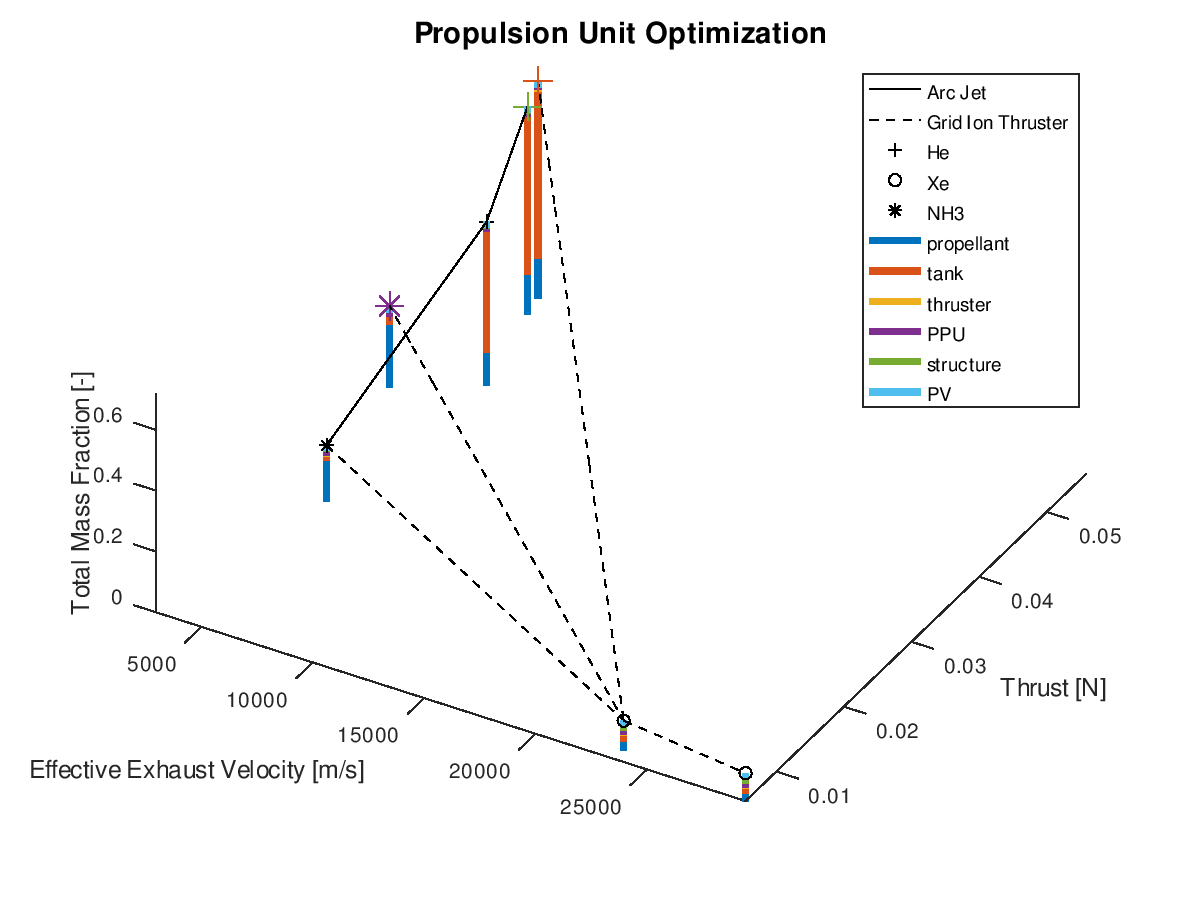
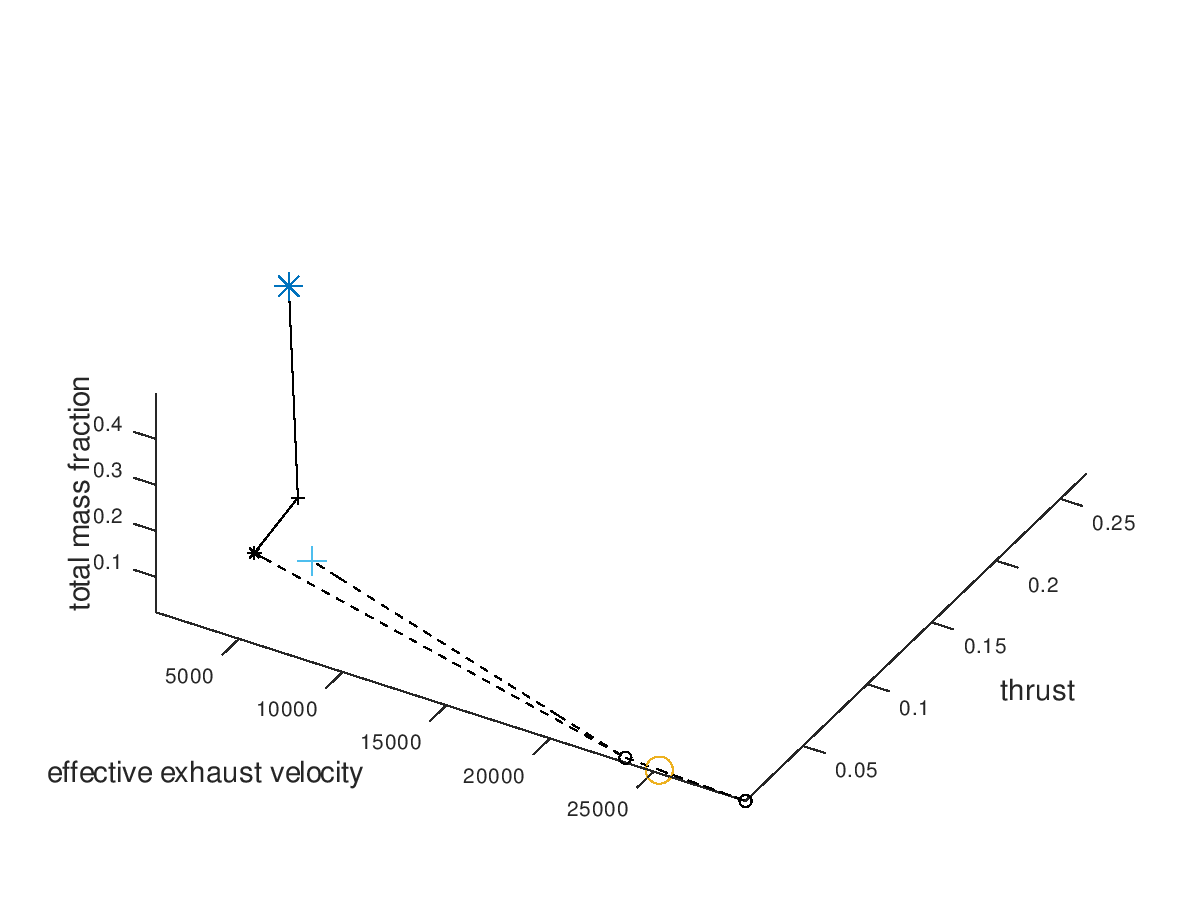
The first example is a 2d visualization, where the y-axis has been assigned to total mass fraction, the line style to propulsion system type, the line color to effective exhaust velocity, the marker to propellant and the marker color to thrust. Additionally, the stacked bar charts have been activated. As the y-axis corresponds to the total mass fraction, each bar of the stacks will correspond to the mass fraction of the respective subsystem. Only the best lineage is selected for visualization. The visualization system returns the following figure:
In the
figure above, we can examine how the mass fraction of each subsystem evolves as
the design of the system becomes optimal. In this simplified example, we can
see that the majority of the decrease of the total mass fraction can be
attributed to the reduction of the propellant and tank subsystems. Of course,
for this shrinkage to happen and the electric propulsion system to be able to
achieve the mission requirements, additional adjustments in other aspects of
the systems are being made by the optimization algorithm. Specifically, between
the starting and the final design point we can see that the propulsion system
type changes from Arcjet (solid line) to Grid Ion Thruster (dashed line), the
propellant changes from He (crosshair marker) to Xe (circle marker), the
effective exhaust velocity is increased (line color turns deep red from light
blue and “jet” is the chosen colormap) and the thrust is decreased (marker
color turns deep blue from deep red and “jet” is the chosen colormap).
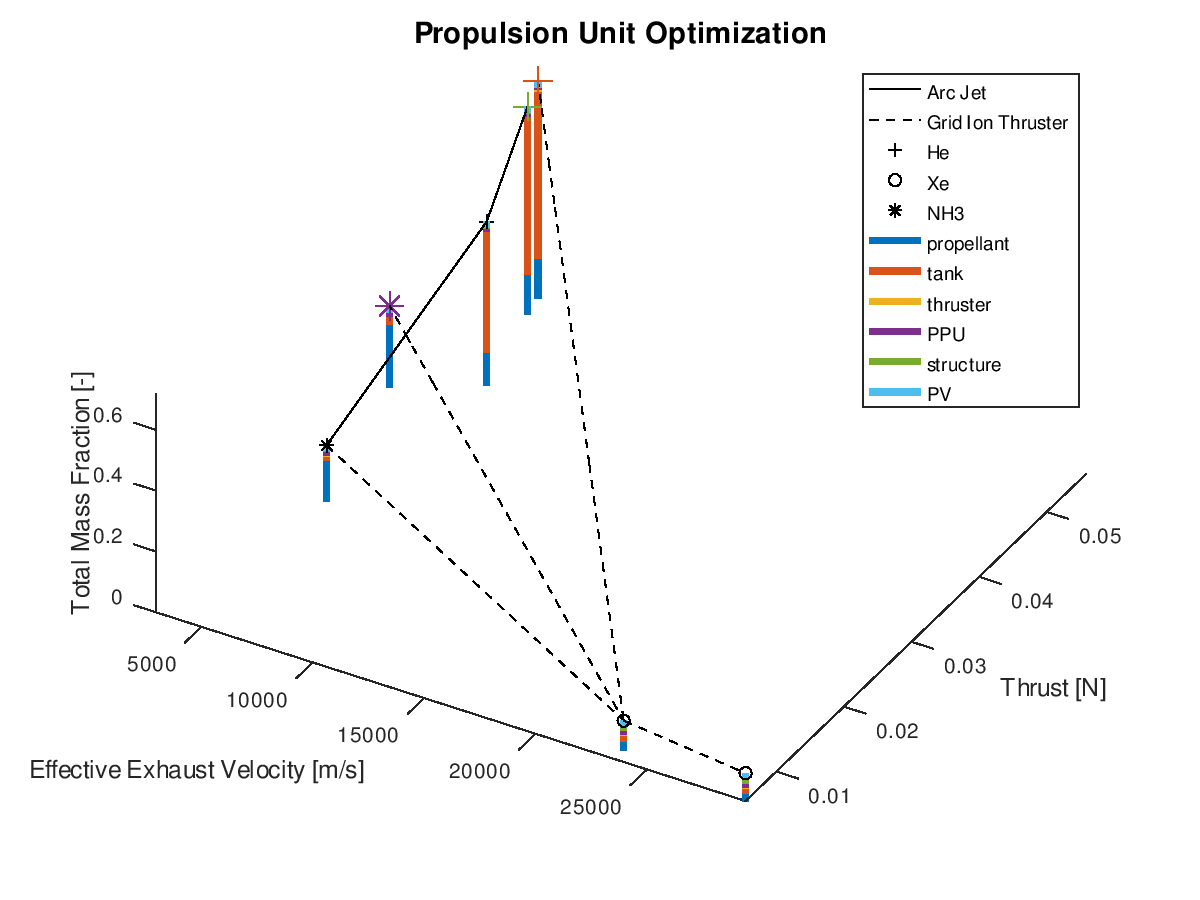
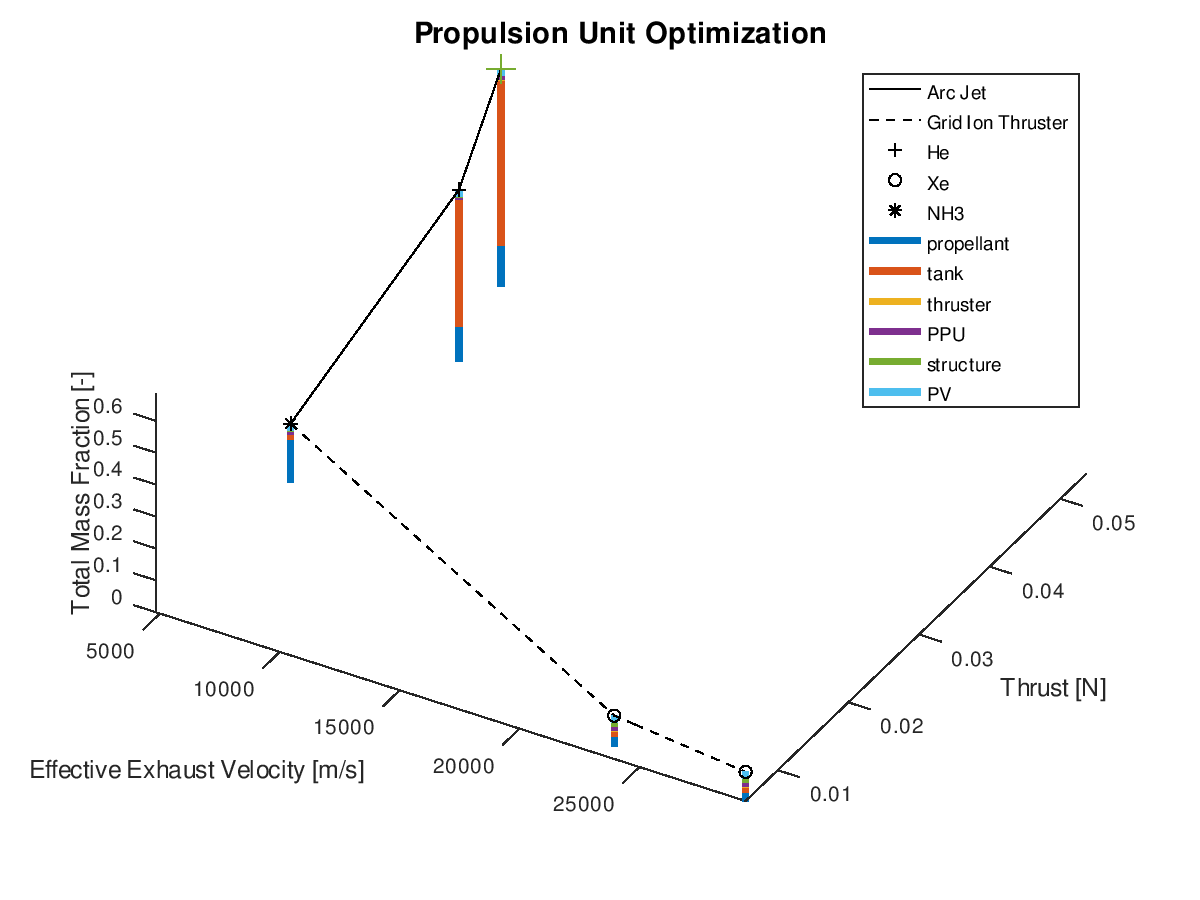
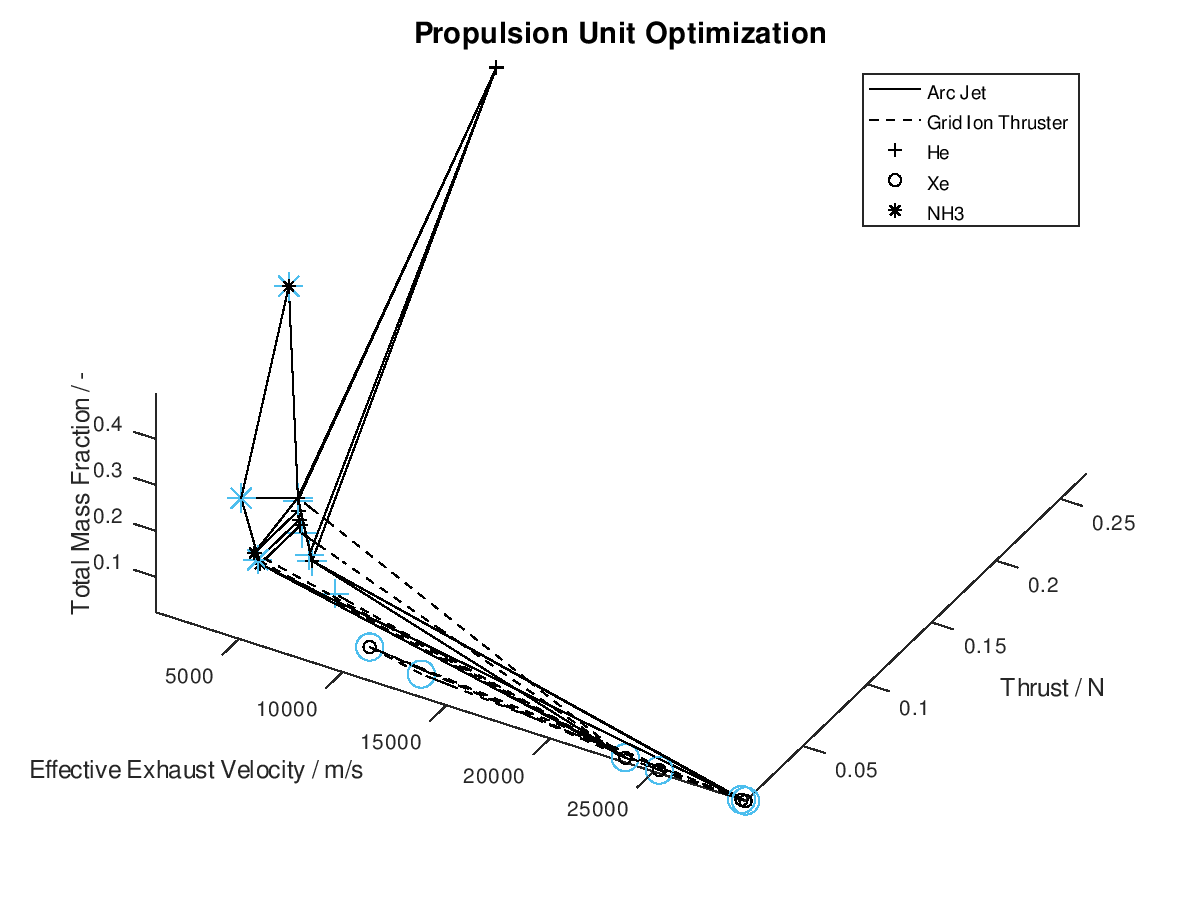
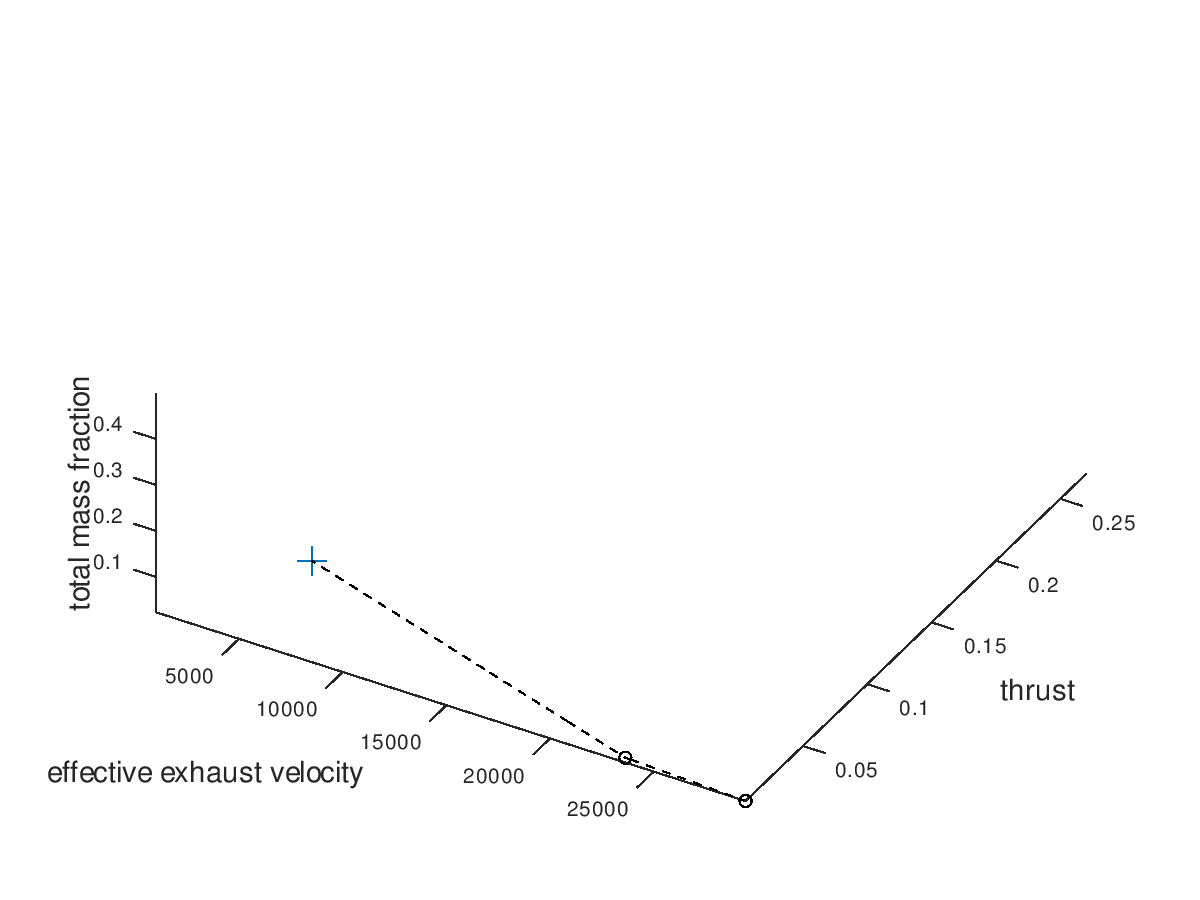
The stacked bar graphs can also be activated in 3d visualizations. In this next example, the x-axis has been assigned to effective exhaust velocity, the y-axis to thrust, the z-axis to total mass fraction, the line style to propulsion system type and the marker type to propellant. Only the best lineage is selected for visualization. The visualization system returns the following figure:
Like the
previous example, it’s easy to point out that the reduction of the total mass
fraction can be greatly attributed to the reduction of the propellant and tank
subsystems.
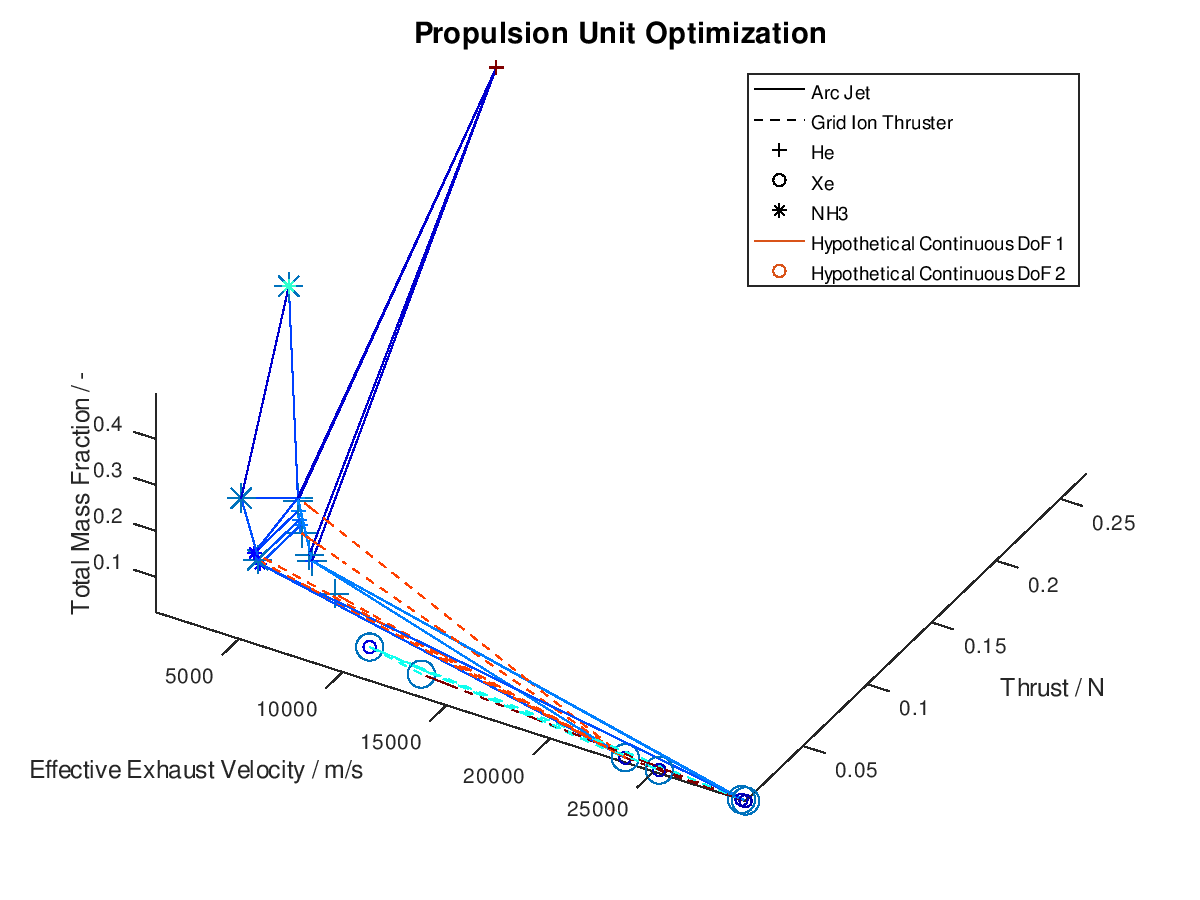
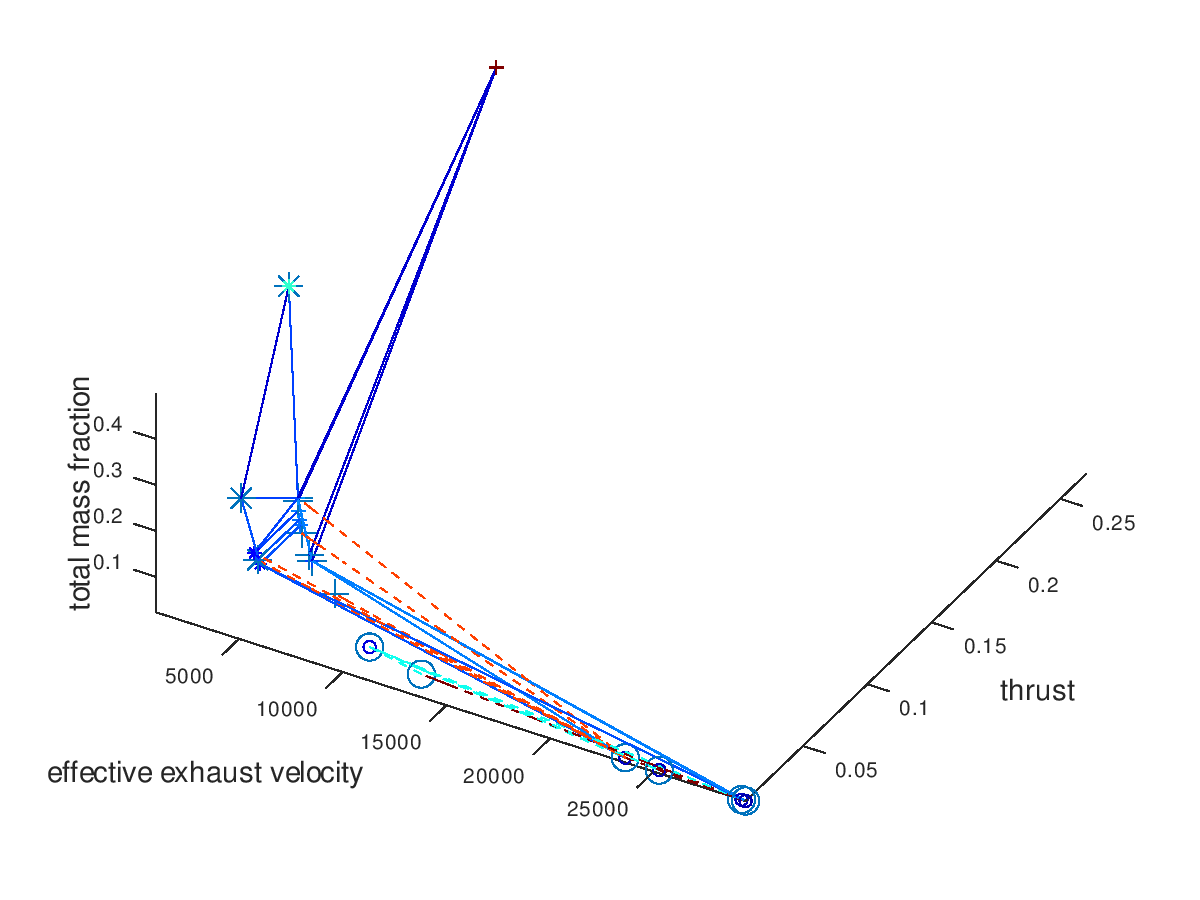
When using the stacked bar graphs in the 3d plot, it is also practical to include more lineages in the visualization. Selecting the three best lineages, the visualization system returns the following figure:
After this
final feature was implemented, additional refactoring of the code was done to
simplify certain parts and achieve improved extendibility and readability.
Refactoring the code was also done to end up in a restructured organization of
functions into subfolders. As the visualization system was designed with
flexibility, modularity and extendibility in mind, it is consisted of more than
100 functions. For this reason, a function dependency graph proved a great aid
for understanding the existing dependencies and making the appropriate
refactoring and restructuring decisions.
Finally, additional
documentation was created for this project to accompany the blog posts during
GSoC. All details regarding the available options and settings for configuring
the visualization system according to specific needs can be found in the
documentation. There, one can also find ready to use XML input file templates
which correspond to the visualizations found in all GSoC blog posts.
Congratulations
if you ‘ve made so far, this was the last long post! A final report will also
be released very soon!
This is the
second in a series of blog posts, where I am documenting the progress of my
project and my experience working with aerospaceresearch.net for Google Summer
of Code 2019.
Last time I
went into details about the often synonymous concepts, in the engineering world,
of designing and optimizing a system. The provided context served as a prerequisite
for explaining the purpose and the motivation behind both the KSat project, as
well as my contribution in the project, which is the development of an automated
visualization system to explore different design points, gain insights about
the optimization process and the genetic algorithm’s performance, aid in
debugging and more. In case you missed it and you would like to have more
information, you can find the first blog post here: https://aerospaceresearch.net/?p=1542
. In fact, I highly recommend that you have read the first blog post before
moving on with the second one.
From this point on, this blog post will focus on the
progress during the second coding period. Before I get into technical topics,
since I am documenting the whole experience, I would like to write a couple of
words about the collaboration and the communication within aerospaceresearch.net.
Like mentioned in the first blog post, everyone inside the organization has
been extremely welcoming and helpful even from the pre-application stage. As it
is to be expected during the second coding period, I was even more familiar
with my project as well as with the exact fit of my work in the bigger picture.
The communication with my main mentor, Manfred, continues to take place in an
almost daily base for anything related to my work and I would like to thank him
one more time for his valuable input and our great collaboration.
Regarding the technical aspects of my project, attention was first given in making the visualizations more presentable and readable. For this purpose, the structure of the xml that serves as an input to the visualization system, was extended to accommodate the following functionality:
-) Application of custom axes limits or limits that are
calculated from the optimization data.
-) Definition of viewing angle for the 3d plot.
-) Definition of plot title.
-) Definition of axes labels that correspond to
degrees-of-freedom (DoFs) that are assigned in x-, y- and z- axis.
-) Definition of legends that correspond to DoFs that are
assigned in line style and line color as well as marker and marker color.
Some additional options like defining the font size for the
title, the labels and the legends are available. The above functionality is more
or less self-explanatory, but in order to make things more tangible the
following visualizations from the first blog post are presented. The difference
here is, that the visualizations have been properly annotated by activating the
corresponding options through the xml file.
The first visualization from the first blog post, would take the following form:
In the figure above, I have defined “Propulsion Unit Optimization” as the title to applied on the plot as well as “Effective Exhaust Velocity / m/s”, “Thrust / N”, and “Total Mass Fraction / -“ as the labels of the x-, y- and z- axis correspondingly. In addition, I have specified that the axes limits should be calculated from the optimization data and that the viewing angle should be [azimuth, elevation] = [30, 60]. I have also enabled the legend for the remaining of the activated DoFs, which in this case are propulsion type and propellant. As it can be seen on the legend, propulsion type (arc jet or grid ion thruster) has been assigned to line style (solid or dashed), while propellant (He, Xe or NH3) has been assigned to marker (crosshair, circle or star). The chosen font sizes in this example are 14 for the title, 12 for the labels and 9 for the legends. At this point it should be noted that some of the above options, concerning the appearance of the visualization, were also manually applied at the corresponding visualization of the first blog post. The difference here is, that their automatic application has now been implemented as a series of activatable options in the xml file.
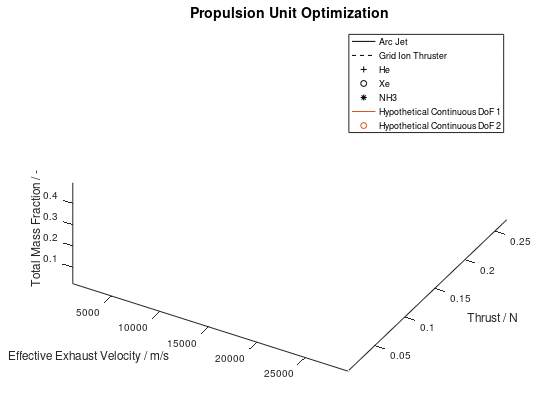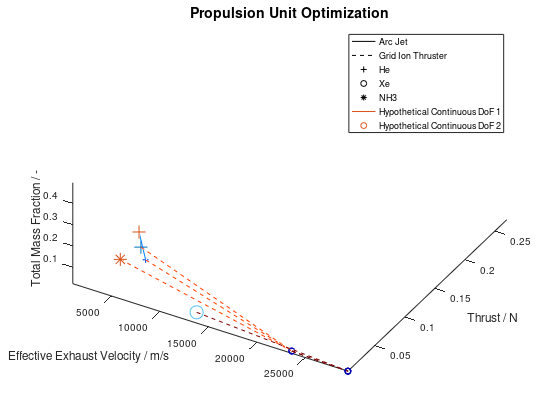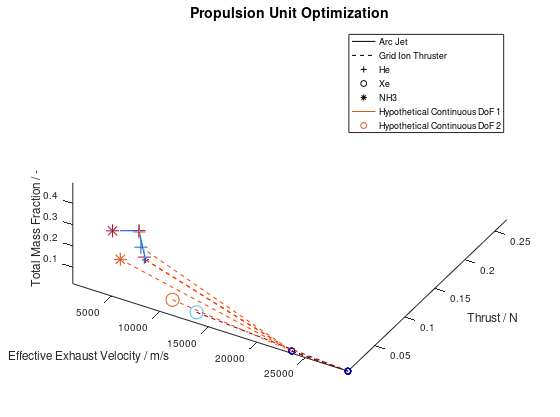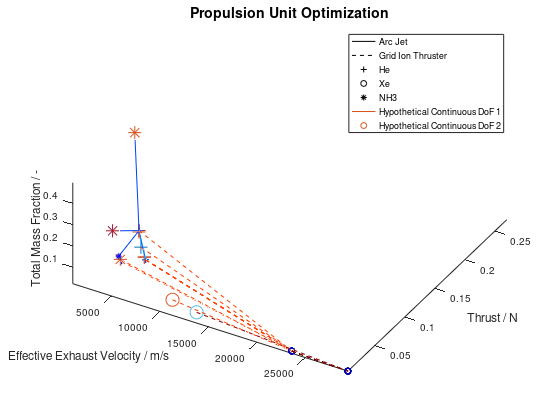
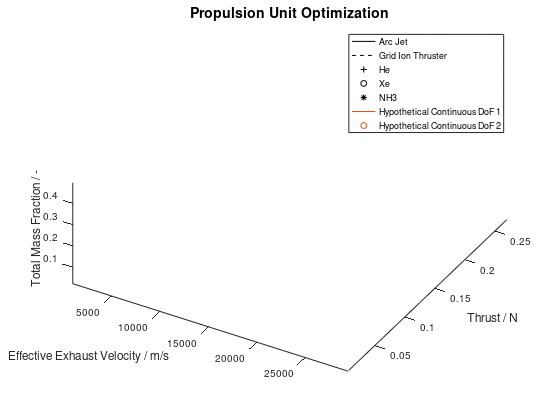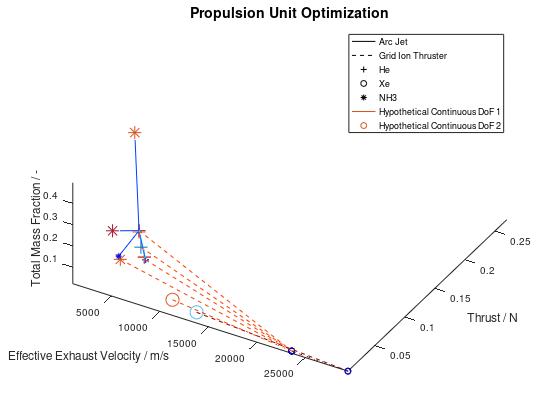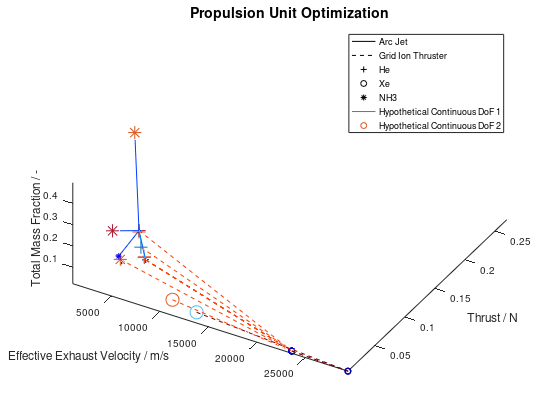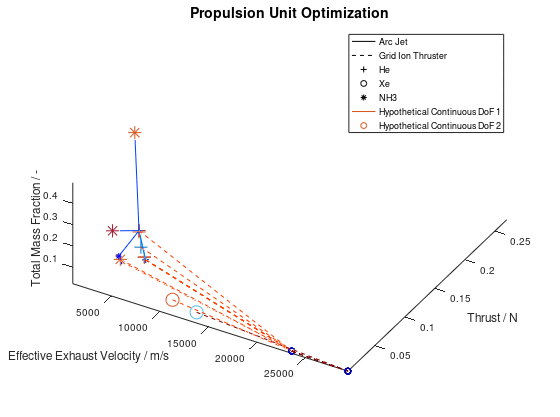
Now that we have an idea about the way in which the majority of a visualization’s elements are annotated, lets also see how potential additional continuous DoFs that are assigned to line and marker color are presented. For this purpose, we are going to use the last visualization from the first blog post, which would take the following form:
The difference in this visualization compared to the
previous one is, that two additional hypothetical continuous DoFs have been assigned
to line and marker colour. To indicate this, the corresponding DoFs “Hypothetical Continuous DoF 1” and “Hypothetical
Continuous DoF 2” are included in the legend with a colored line and mark. Notice
that are all other elements in the legend are black. The colored elements
indicate that the value of these continuous dofs corresponds to the line and
marker color in the visualization.
Now that we have covered the annotation of the visualizations, lets move to the remaining implemented functionality. A second type of visualization, a 2d visualization, was added in the visualization system. The motivation for the 2d plot is similar to the motivation for the 3d plot. Different system DoFs can be assigned to y-axis, line style and color as well as marker style and color. Notice that the x- and z-axis are no longer available to the user. At this point you may ask what the purpose of the 2d plot is then. In the 2d plot the x-axis corresponds to the generations of the system’s evolution, thus the 2d plot can be used to acquire a clearer picture regarding the chronological order in which different lineages evolve through different design points.
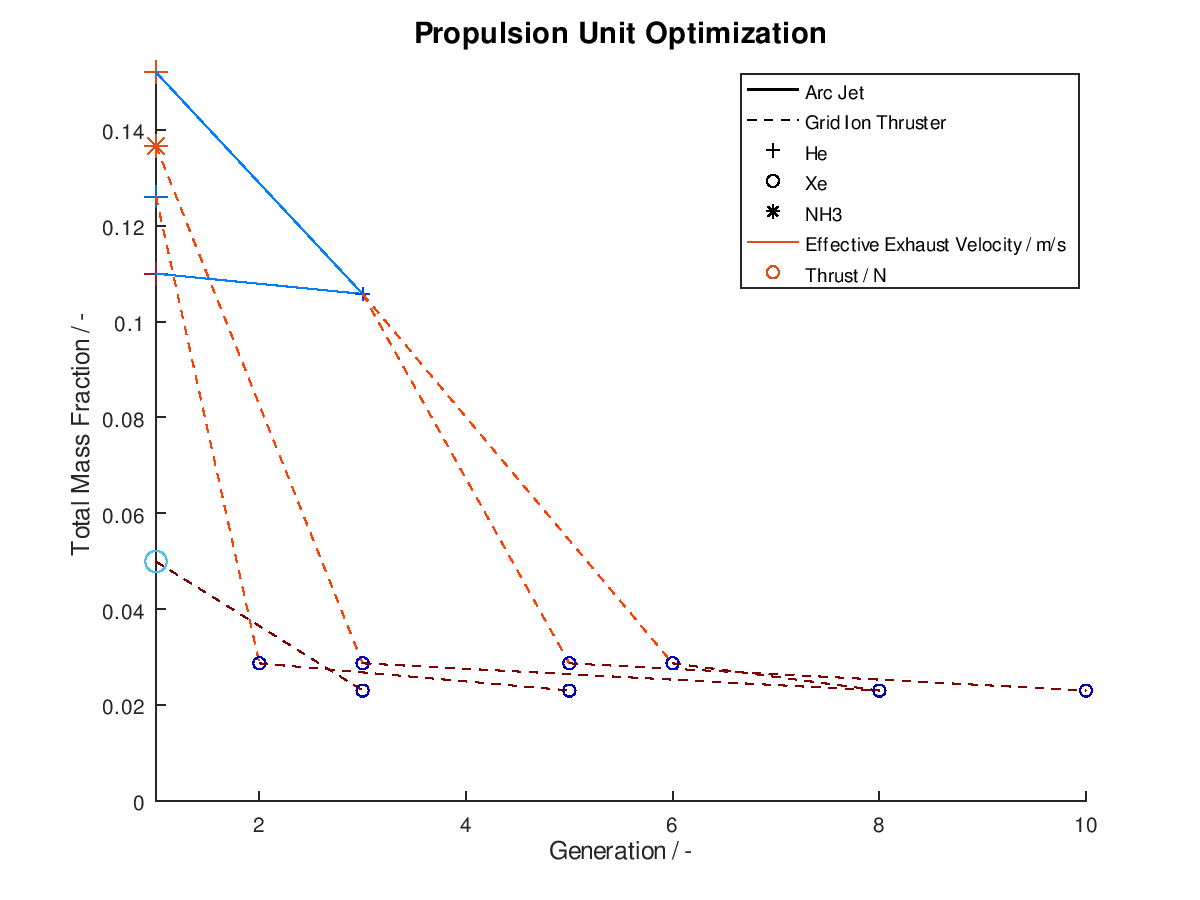
As usual I am going to give a practical example. I assign total mass fraction to y-axis, propulsion type to line style, propellant to marker, effective exhaust velocity to line color and thrust to marker color. I deactivate the visualization of failed mutations, I sort the lineages by total mass fraction and I keep only the 5 best lineages. I also activate the use of the implemented annotations. The plotting system returns the following figure:
As we can
see from the figure above, all lineages converge to almost identical final design
points. One lineage achieves this in just 3 generations, while another one need
as much as 10 generations. In between of improved design points, we can also observe
the number of generations where failed mutations occurred. For the lineage that
converges on the 10th generation we can see that the successful mutations
take place at the 3rd, 6th and 10th generation.
This means that the mutations of the generations 2, 4-5 and 7-9 were failed
mutations.
Another
implemented feature is the ability to save the generated visualizations in a
desired file format. This is required in order to review the progress of the
optimization process after the execution of an optimization cycle. For this purpose,
the following functionality was implemented as an activatable option through
the xml file.
-) Saving
of the visualization in one or more file formats. The available file formats
are: *.ps, *.eps, *.jpg, *.png, *.emf, *.pdf
-) Generating
filenames according to input case number, input/mission parameters and plot
case number.
In order to
avoid loss of any generated visualization it is important that the generated
filenames always remain different regardless of the number of visualizations or
the activated filename options. For this purpose, a hard-coded fail-safe check
was also included. A sample generated filename could be “input_case_1_totalimpulse_112670_deltav_686_plot_case_1”.
In this case, the input case number, the mission parameters (total impulse and velocity
increment) along with their corresponding values and the plot case number, were
all included in the title. For distinction purposes between different
visualizations the plot case number is always included in the title, while in
the absence of mission parameters the input case number is also automatically
included.
Finally, another way to reap more potential insights from the visualizations is to include the dimension of time in them. This was achieved to a certain extend with the use of the 2d plot where the x-axis corresponds to the generations. There is another way to do so, where the graphics objects that form the visualizations are animated through a series of frames that follow the evolution of the system that is being optimized. The output is a series of frames that form a gif animation, rather than a single snapshot. The graphics objects can be animated in two different ways.
According to the first approach, the graphics objects are animated separately for each lineage. The sequence of the design points that correspond to the best lineage are animated first, then those that correspond to the second best and so on. This animated version of the last visualization of the first post, is the following:
In the
animation above, only the 10 best lineages have been included. The frame rate
of the animation is defined at 2 fps through the xml file.
The other
way in which the graphics objects of a visualization can be animated, is for
all lineages together. In this case, the sequence of the design points of all selected
lineages is animated according to the progression of the generations. Design points that appear on the same frame
correspond to mutations of different lineages that took place on the same
generation during the optimization process. This animated version is the
following:
It should
be noted that the examples for which the animations were applied, are simplified,
thus a certain visual overlap occurs between different lineages. This causes
the animations to appear stagnant at times, while what is really happening is
that some lineages follow an identical sequence of design points as others. These
design points have already appeared in the visualization due to already
visualized lineages or due to lineages that have advanced through them at an
earlier generation, giving the illusion that the animation remains stagnant at times,
but this is not the case.
One final
thing to mention is, that not only a 3d plot but also a 2d plot can be animated
in a similar fashion.
Summing up
this second blog post, we got a brief overview as well as a quick demonstration
of the newly added features. We saw how these features build on top of the
existing ones and open the possibilities for further exploration of the
evolution data. There are some cases where minor bug fixes are required, and potential
improvements and extensions have already been identified. Documentation is also
going to be developed, but all that is work for the following weeks …
Congrats
for making it through the second blog post and many thanks for reading!
With these series of blogs posts I will be documenting the progress of my project and my experience working with aerospaceresearch.net for Google Summer of Code 2019.
First, a few words about my mentors from aerospaceresearch.net and the communication between us. The main mentor of my project is Manfred Ehresmann, with whom we discuss almost daily for everything regarding my project. Since there is also a lot of development going on from Manfred’s side, effective communication for defining my project’s requirements, coming to common ground regarding technical matters that affect the work of both and solving any issues that arise has been key to the progress of my project and I am very happy that we have effortlessly achieved this. My second mentor is Andreas Hornig and since he is the main mentor of other projects, we communicate on a less regular basis for everything regarding my work with aerospaceresearch.net and my participation in GSoC. Andreas has also been incredibly helpful throughout this time, from guiding us through the application process to taking care of our onboarding in the organization and making sure that we have everything set up to be able to work undistracted on our projects. The platform that we use for our communications is Zulip.
Now it’s time for an introduction to the GSoC project and my contribution. Manfred is developing a software for designing space craft systems, currently limited to electric propulsion units for satellites. Since in the engineering world, the word “design” is most of the times synonyms to the word “optimize”, the later is actually the goal of the software. That is, to use data from existing systems and additional resources along with system modelling and scaling rules, in order to apply a genetic algorithm that can design an optimized space craft subsystem, which is an electric propulsion system currently, for different mission scenarios. This optimization is not straight forward, especially when there are a lot of sub-systems with non-linear interactions between them to be included in future development. Additionally, the algorithm itself has a lot of hyperparameters, whose tuning is a non-trivial task. For this reason, it is useful to have a way to evaluate the progress of the optimization process, in order to gain insights that can either lead in improvements of the algorithm or be directly utilized my human designers as well as aid in debugging of newly added features. This is where my contribution to the code comes. I am developing a visualization system which can be used to automatically generate useful visualizations from the evolution data of the genetic algorithm according to user defined parameters.
Let’s say a few words about the work that has been completed during the 1st coding period. During the previous weeks I have been laying out the architecture of the visualization system, defining the structure of the xml file that is used by the user to communicate with the system and implementing the first type of plot, the 3d plot. By this time, you may wonder what this plot is, in which way it is using the evolution data and how is it even useful in the first place! To get a better understanding, let’s talk about optimization for a second.
What does it mean to optimize an electric propulsion system? Well, first let’s define what it means to design a system. To design a system means to select the appropriate values for some variables of the system. These are here the effective exhaust velocity, thrust, propulsion type, propellant and more. For initial system design these are enough to fully define the rest of the systems parameters by using known system modelling equations and scaling laws equations as well as any system or mission requirements, for example total impulse, velocity increment, propulsion power. We can name the first set of variables, independent degrees-of-freedom (dofs) of the system, and the second set of variables that are calculated from the first, dependent dofs. The goal of the design process is to come up with a system that achieves a certain performance. If we define a specific performance criterion (ex. mass fraction of the electric propulsion unit), then by systematically searching for the best (optimal) values of the independent dofs we can come up with a system that best meets this performance criterion (ex. has the lowest mass fraction). This process is called optimization. In our case, a genetic algorithm is used for searching the optimal values of the independent dofs, which can be either continuous variables (ex. effective exhaust velocity, thrust) or discrete variables (ex. propulsion type, propellant). The electric propulsion system has also additional dependent variables/parameters (ex. mass fractions and efficiencies of sub-systems) which are calculated from the independent variables.
By visualizing the evolution data, we want to observe how the system moves along the design space during the optimization process. We want to see whether the mutations of the system are successful or not and we want to identify the design points where the system converges and possibly observe any other piece of information or pattern that can help improve the optimization and better understand the optimal designs. For this purpose, we want to plot different system variables (ex. effective exhaust velocity, thrust, propulsion type, propellant etc.) against the objective criterion (ex. system mass fraction). Using a 3d plot we can assign the objective criterion to the z-axis, the effective exhaust velocity to the x-axis and the thrust to the y-axis. In order to include additional dofs into the visualization, we can encode them into other aspects of the visualization, specifically line style, line color, marker and marker color. Continuous or discrete dofs can be assigned to line color and marker color by mapping the values of the dofs to the colors of a corresponding color map. Additionally, discrete dofs can be assigned to line style and marker by mapping the values of the dofs to a corresponding set of line styles and markers.
Using the xml file, we can define which system dofs (ex. system mass fraction, effective exhaust velocity etc.) are assigned to each plot dof (x-axis, y-axis, line style, line color etc.). The key capabilities of the visualization system can be summed up in the following points:
-) Flexible
assignment of system dofs to plot dofs.
-) Selection of color maps, line styles, markers etc. to be used in the visualization.
-)
Definition of default visualization style.
-)
Activating or deactivating the visualization of failed mutations.
-) Defining
custom visualization style for failed mutations.
-) Defining
custom visualization size for seed points.
-) Defining
multiple plot cases.
-)
Specifying active input cases.
-) Sorting lineages by a specified dof.
-) Selective plotting of lineages.
In order to get a better understanding of the capabilities of the visualization system, let’s go over a few potential use cases. Let’s say that an optimization campaign has been completed and we would like to start exploring the evolution data that has been created by the genetic algorithm.
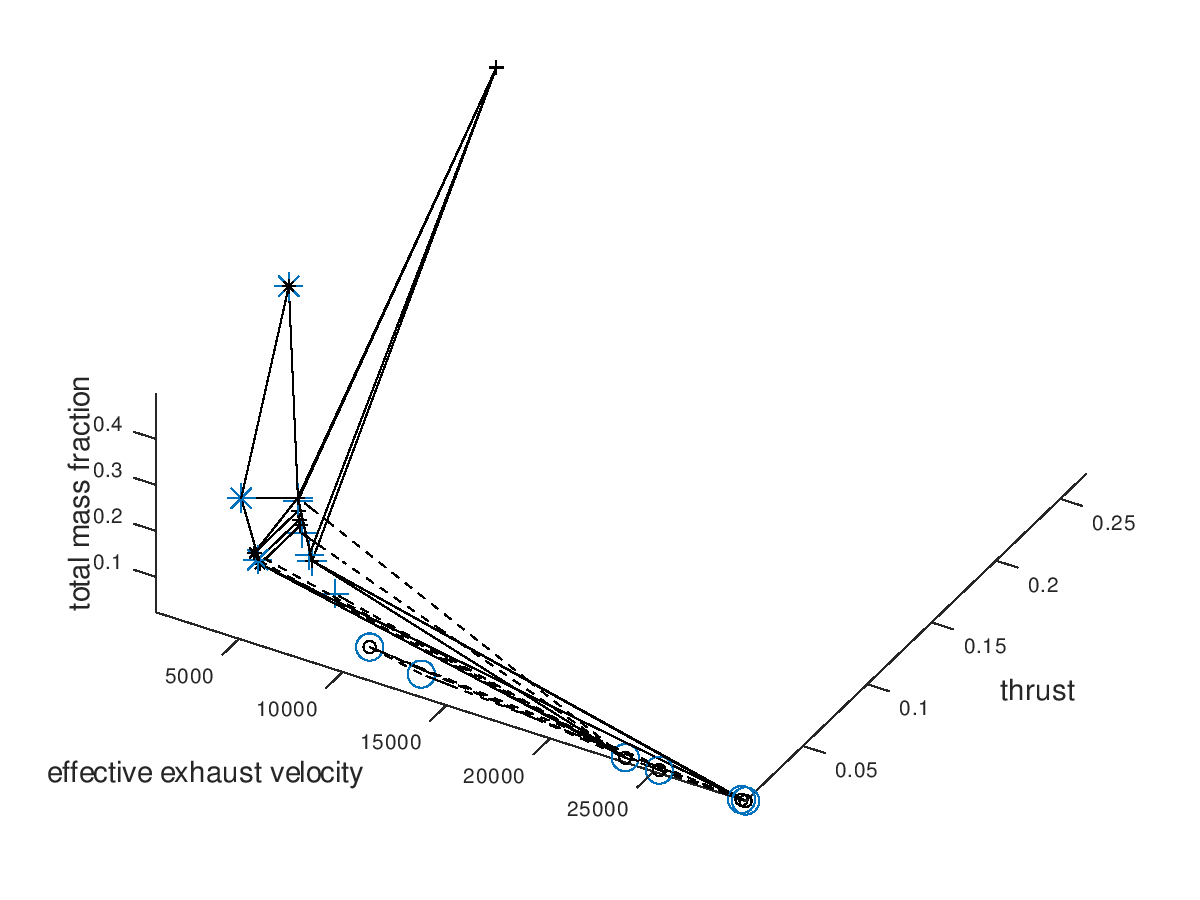
First, I assign the system dofs, for which I am interested, to corresponding plot dofs. In these examples I am going to assign effective exhaust velocity to x-axis, thrust to y-axis, total mass fraction to z-axis, propulsion type to line style and propellant to marker. I will also define that the possible propulsion systems (arcjet, grid ion thruster) are going to map to line styles (solid, dashed) and the possible propellants (He, Xe, NH3) are going to map to markers (crosshair, circle, star). I am also going to activate the visualization of failed mutations, but I am going to leave deactivated the custom visualization style for failed mutations, since with this first visualization I just want to observe how the design space has been explored by the algorithm. The visualization system returns the following figure:
In the figure above, we can see that only a certain portion of the design space has been explored. The seed points are represented by the large blue markers. Since line color and marker color has not been assigned to a system dof, they are black, which is the default visualization style that I have specified.
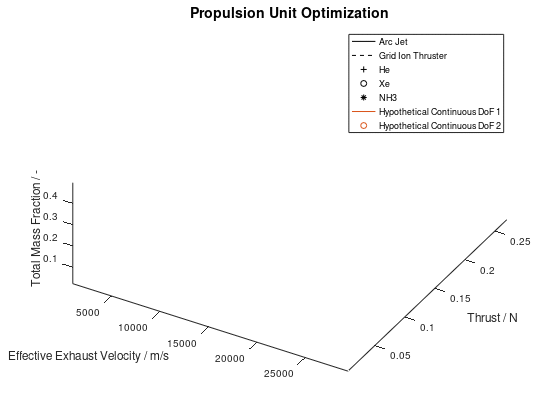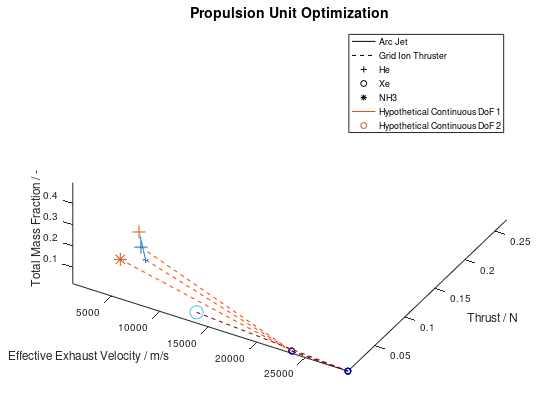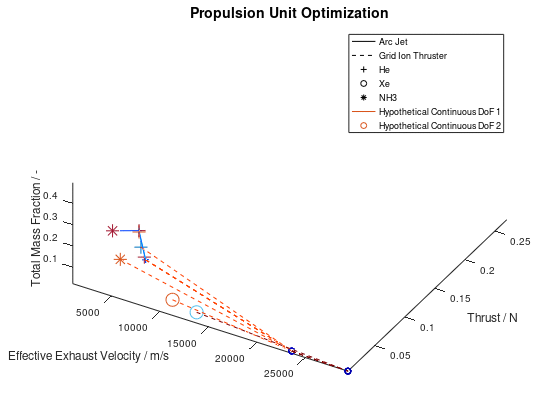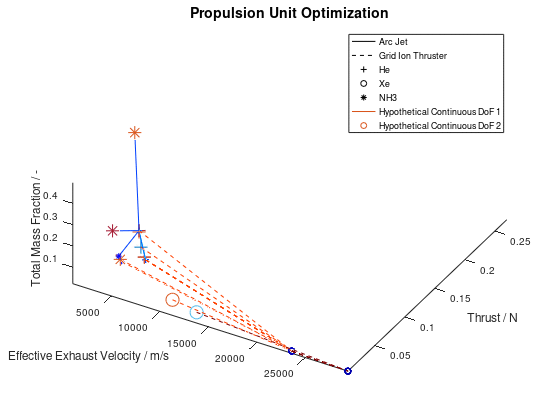
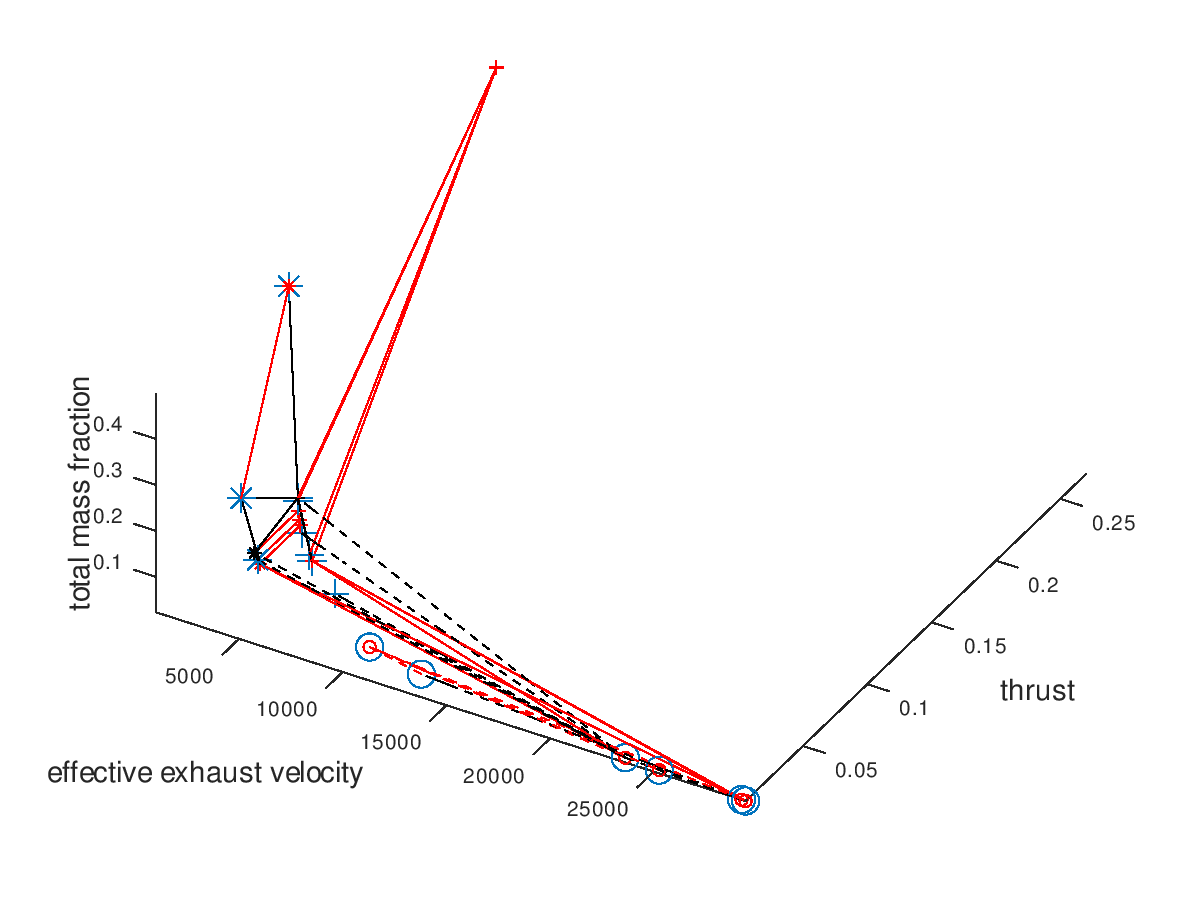
Now we are going to use the capabilities of the visualization system to gradually get a deeper understanding of our data. It would be interesting to see which portion of the mutations are successful. For this purpose, I am going to activate custom visualization style for the failed mutations, and I will specify red color for line color and marker color. The visualization system returns the following figure:
From the figure above it is clear that the majority of the mutation are failed mutation. For this reason, I would like to visualize only the successful mutation. To do this, I deactivate the visualization of failed mutations. The visualization system returns the following figure:
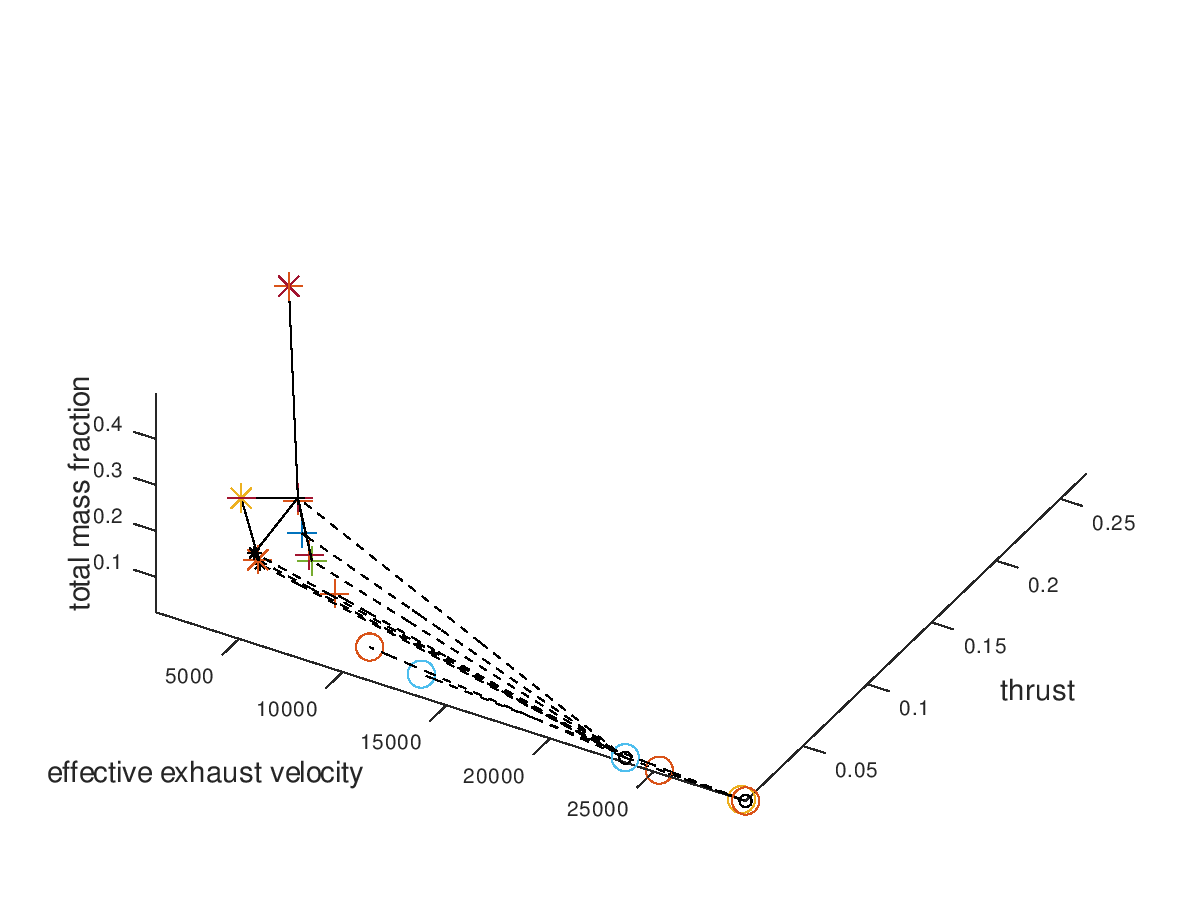
The trend of the optimal design points to converge to high effective exhaust velocity, low thrust, grid ion thruster propulsion (dashed line) and Xe propellant (circle marker) is easily recognizable. Note that the seeds points have now different colors, which is currently a bug rather than an implemented feature. Next, I want to visualize only the three best designs. For this purpose, I am going to define the total mass fraction as the sorting criterion of lineages and select “increasing” as the sorting direction, since the best designs are the ones with the lowest total mass fractions. The visualization system returns the following figure:
We can see that all 3 lineages converge to the same design point. It would be interesting to also explore the behavior of the 3 worst lineages. The visualization system returns the following figure:
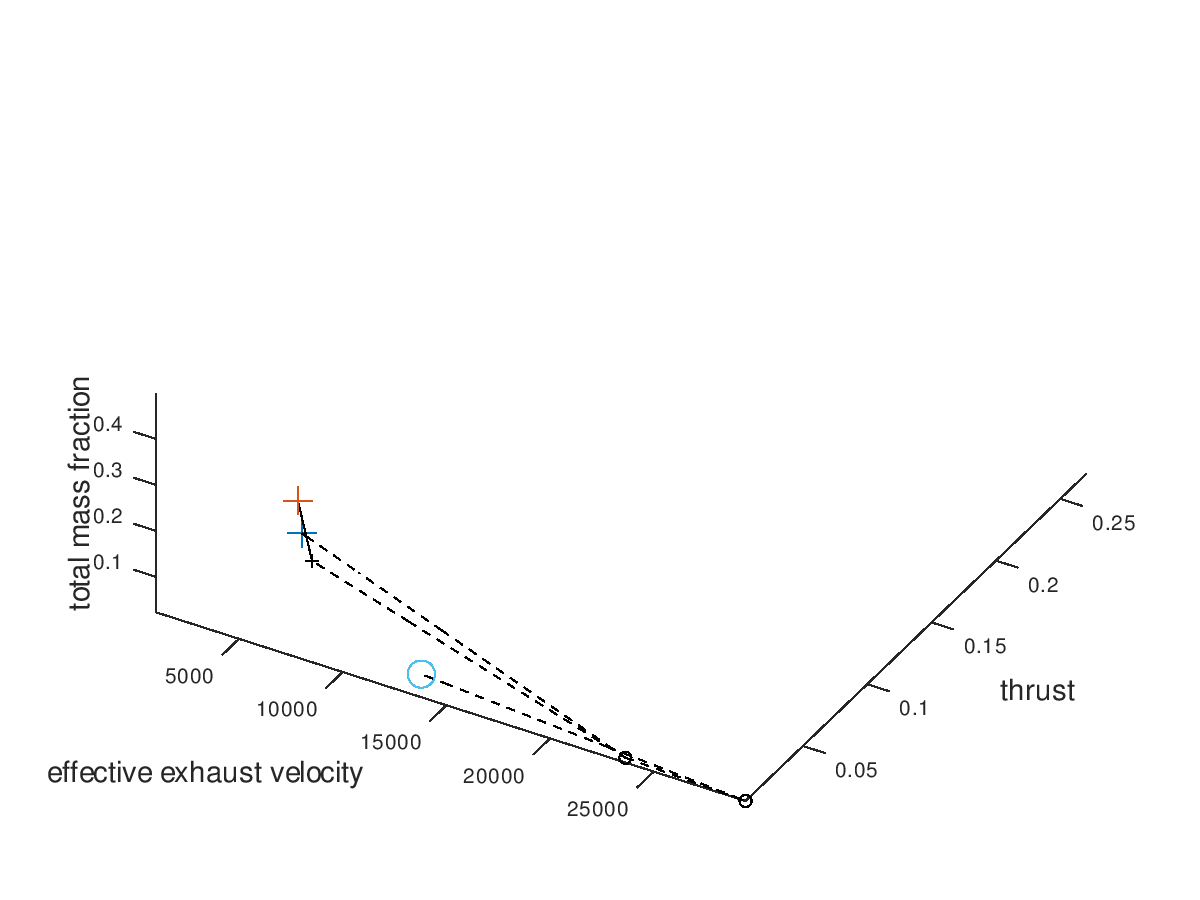
By surprise, the three worst lineages also converge to the same optimal design point. This means that our algorithm is very robust to the selection of initial seed points, at least for this simpler example. To confirm that all lineages converge to the same design point, I am also going to visualize only the worst lineage. The visualization system returns the following figure:
Indeed, all lineages converge to the same design point because the worst one does so. At this point we could come up with more visualizations to explore, but for the purpose of briefly demonstrating the flexibility of the visualization system these examples are considered enough.
One last thing to demonstrate is what the visualization would look like when line color and marker color are also assigned to a system dof. That would be the case if the model of the electric propulsion system had additional independent dofs. For this example, we are going to assume that two hypothetical continuous dofs are assigned to line color and marker color respectively. I am going to define “jet” as the color map for both line color and marker color. I am also going to activate the visualization of failed mutations and include all lineages in the visualization. The visualization system returns the following figure:
As we can see from the figure above, the two additional dofs have been encoded in the visualization.
Summing up
this first blog post, there are still a few things that need to be implemented
in the visualization system regarding the presentation of the 3d plot (labels,
legends, viewing angle, limits etc.) which will be added soon. An additional
type of plot as well as animation capabilities are going to be added during the
following coding periods. But for now, …
Many thanks
for reading and cheers to the space and GSoC community!